During the second and third week, I spent most of my time understanding and enhancing yt’s data_objects module. In addition, I switched to Codecov for coverage reporting from Coveralls.
1. Coverage Tool
What made me switch to Codecov?
After one week of Coveralls integration, we started facing few issues with the tool. On May 24-26, Coveralls was facing Job Enqueuing Issue, thus in spite of successful builds no Coveralls reports were getting generated. Delay in posting their service status exacerbated the issue with no clue of the root problem. As a result, we decided to integrate Codecov which was already being used in unyt - yt’s package for handling numpy arrays with units.
CodeCov features as compared to Coveralls:
-
Better Reporting UI: Codecov’s portal is clean and intuitive.
")
-
Coverage Sunburst: Sunburst is an interactive graph that enables to navigate into project folders in order to discover files that lack in code coverage. The size of each slice is the total number of tracked coverage lines, and the color indicates the coverage.
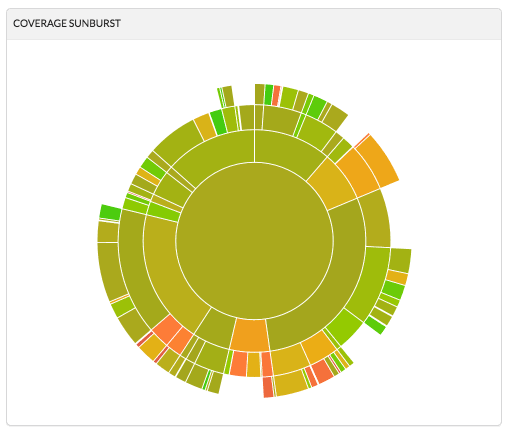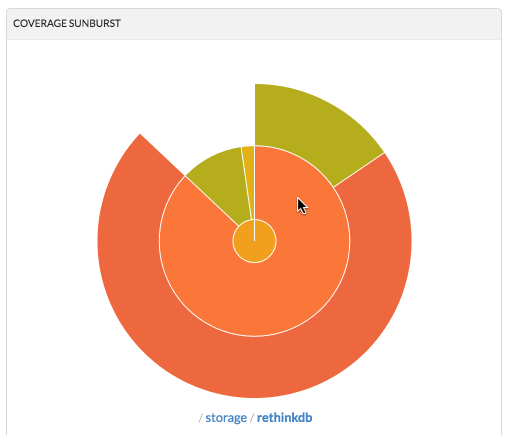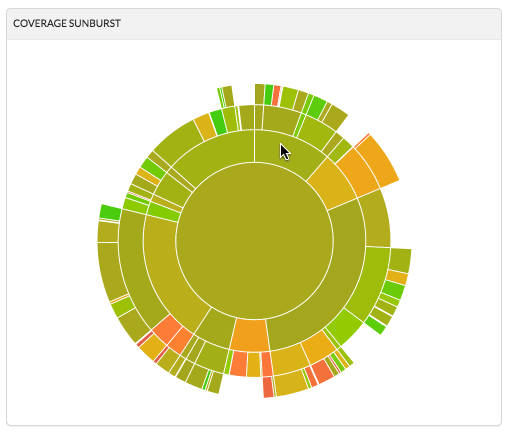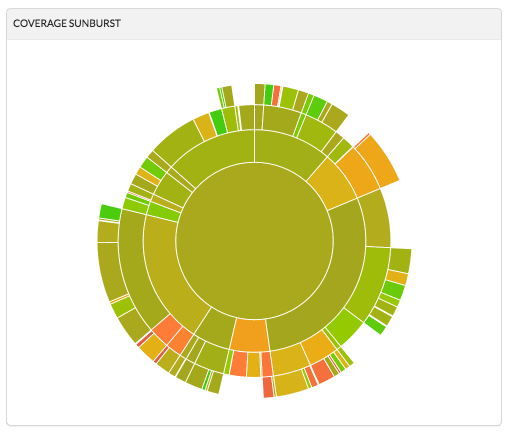
Codecov sample Sunburst yt’s current coverage Sunburst -
Ability to see partial reports: yt’s Travis build consists of 5 builds in Linux and 1 OSX build. As soon as build in any one of the environment is completed, the results are published to Codecov and we can see the partial coverage reports ( with a clear warning from Codecov stating that the result is temporary and might change once the complete build is done).
-
Reliability: One of the biggest advantages of any service is reliability and Codecov has not disappointed so far.
With a coverage analysis tool in place, now it is easier for the code reviewer and the developer to ship code that is thoroughly tested. The aim is to identify bugs and prevent unexpected behavior during development cylce.
2. Restructuring Travis Build
At present flake8 tests are run for all the 6 environments. Now using, Travis’s Build Stages feature, I have broken down the pipeline in two stages. In the first stage, we do linting by running only the flake8 tests on the pull request. Once this stage is passed, we start our unit testing in parallel on the 6 build environments. The main advantage of this approach is that it frees up the resources as soon the flake8 tests fails and thus the build process will start another queued job. Not only this approach is clean in terms of “separation of concerns” but is computationally efficient.

3. Improving Test Infrastructure:
I am following the following methodology to improve the test suites:
-
Currently, many of the test cases use real data to test the functionality. These datasets are expensive in terms of computation and disk I/O. Further, these tests are skipped at Travis, making Travis build less reliable. In many of the situations, these tests could be replaced by utilizing fake datasets (eg.
fake_particle_ds,fake_random_ds,fake_octree_ds, etc. ) that are lightweight datasets generated on the fly and does not require any I/O. -
Writing test cases to expose more lines of code to the execution flow. For these tasks, I started with
data_objectsmodule and have sent few PRs. Next, I plan to take ongeometrymodule.
List of PRs sumitted during these weeks:
Merged PR:
- Removed coverage report from Travis Logs and Flake8 with Build Stages
- Updating tests to use fake dataset instead of real data
- Updating config to not fail the pushed patch
- Removing the dependency from real datasets
- Codecov Integration
- Enhanced test cases for image_array.py in data_objects
- Coveralls integration